
در سال جاری، شرکت چینی هوش مصنوعی DeepSeek از یک چتبات به نام R1 رونمایی کرد که توجهات زیادی را به خود جلب کرد. این جلب توجه نه تنها به دلیل عملکرد رقابتی این چتبات در مقایسه با محصولات برخی از معروفترین شرکتهای هوش مصنوعی جهان، بلکه به خاطر استفاده از مقدار بسیار کمتری از قدرت محاسباتی و هزینه بسیار پایینتر بود. به دنبال این رونمایی، ارزش سهام بسیاری از شرکتهای فناوری غربی به شدت کاهش یافت؛ بهطوریکه شرکت Nvidia، که چیپهای مورد استفاده در مدلهای پیشرفته هوش مصنوعی را تولید میکند، در یک روز بیشتر از هر شرکت دیگری در تاریخ از ارزش خود کاست.
اما داستان این موفقیت به سادگی به نظر نمیرسد. برخی منابع ادعا کردند که DeepSeek بدون اجازه از مدلهای انحصاری OpenAI، با استفاده از یک تکنیک به نام تقطیر (Distillation) به این موفقیت دست یافته است. بسیاری از خبرها این احتمال را بهعنوان یک شوک برای صنعت هوش مصنوعی مطرح کردند و اینگونه القا کردند که DeepSeek روشی جدید و کارآمدتر برای ساخت هوش مصنوعی یافته است.
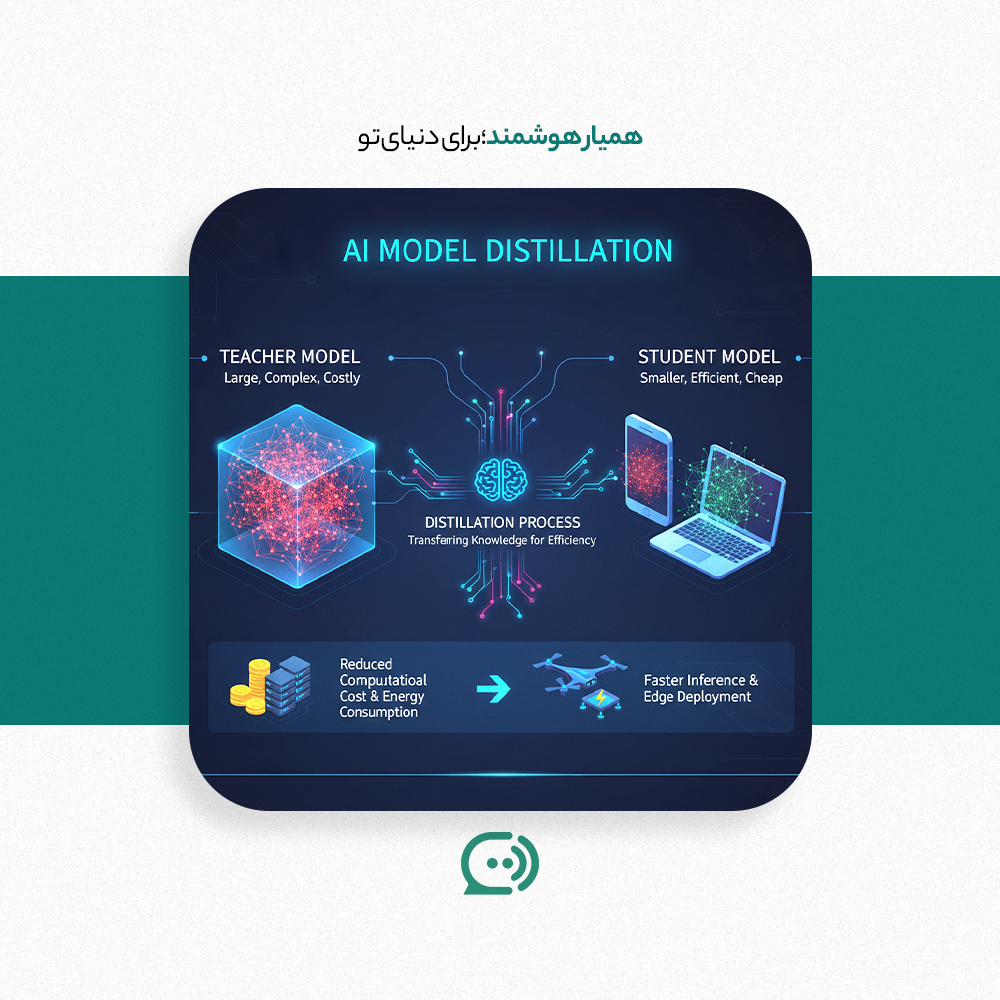
مفهوم تقطیر در هوش مصنوعی
تقطیر، همچنین به عنوان «تقطیر دانش» (Knowledge Distillation) شناخته میشود، ابزاری است که به طور گسترده در صنعت هوش مصنوعی استفاده میشود و سابقهای حدود یک دهه در تحقیقات علوم کامپیوتر دارد. این تکنیک به شرکتهای بزرگ فناوری کمک میکند تا مدلهای خود را کارآمدتر کنند. انریک بویس-آدسر، محقق دانشگاه وارتون، در این باره میگوید:
«تقطیر یکی از مهمترین ابزارهایی است که شرکتها برای بهبود کارایی مدلهای خود دارند.»
دانش تاریک
ایده تقطیر برای اولین بار در سال ۲۰۱۵ توسط سه پژوهشگر از گوگل، از جمله جفری هینتون، که به عنوان پدرخوانده هوش مصنوعی شناخته میشود، مطرح شد. در آن زمان، پژوهشگران اغلب از مجموعهای از مدلها (مدلهای ترکیبی) استفاده میکردند تا عملکرد خود را بهبود بخشند. اما این رویکرد به شدت دشوار و پرهزینه بود. وینیالز، یکی از نویسندگان این مقاله، میگوید:
«ما به ایده تقطیر به یک مدل واحد فکر کردیم.»
این پژوهشگران متوجه شدند که یکی از نقاط ضعف بارز الگوریتمهای یادگیری ماشین این است که تمام پاسخهای نادرست به یک اندازه بد در نظر گرفته میشوند. به عنوان مثال، در یک مدل شناسایی تصویر، «اشتباه گرفتن یک سگ با یک روباه به همان اندازه تنبیه میشود که اشتباه گرفتن آن با یک پیتزا». آنها تصور میکردند که مدلهای ترکیبی اطلاعاتی درباره این که کدام پاسخهای نادرست کمتر بد هستند، در خود دارند. شاید یک مدل کوچکتر (مدل دانشآموز) بتواند با استفاده از این اطلاعات از مدل بزرگتر (مدل معلم) به سرعت به دستهبندی صحیح تصاویر دست یابد.

رشد انفجاری
اگرچه این ایده به سرعت مورد توجه قرار نگرفت و مقاله اولیه از یک کنفرانس رد شد، اما تقطیر در زمانی مهم به میدان آمد. در این زمان، مهندسان متوجه شدند که با افزایش حجم دادههای آموزشی، کارایی شبکههای عصبی نیز افزایش مییابد. به همین دلیل، حجم مدلها به شدت افزایش یافت، اما هزینههای اجرای آنها نیز به طرز چشمگیری بالا رفت.
بسیاری از پژوهشگران به تقطیر به عنوان روشی برای ایجاد مدلهای کوچکتر روی آوردند. به عنوان مثال، در سال ۲۰۱۸، پژوهشگران گوگل یک مدل زبانی به نام BERT را معرفی کردند که به سرعت در پردازش میلیاردها جستجوی وب مورد استفاده قرار گرفت. اما BERT مدل بزرگی بود و هزینههای بالایی داشت. بنابراین، در سال بعد، توسعهدهندگان نسخهای کوچکتر به نام DistilBERT را عرضه کردند که به طور گستردهای در کسب و کار و تحقیقات استفاده شد. تقطیر به تدریج به یک تکنیک عمومی تبدیل شد و حالا به عنوان خدماتی از سوی شرکتهایی چون گوگل، OpenAI، و آمازون ارائه میشود.
نتایج و چشمانداز آینده
با توجه به اینکه تقطیر نیاز به دسترسی به درونمایههای مدل معلم دارد، امکان تقطیر اطلاعات از مدلهای بسته مانند مدل o1 OpenAI به صورت غیرمجاز وجود ندارد. با این حال، یک مدل دانشآموز میتواند با پرسیدن سوالات خاص از مدل معلم و استفاده از پاسخها، به یادگیری بپردازد. این رویکرد تقریباً شبیه به روش سقراطی در تقطیر است.
در همین حال، پژوهشگران دیگر همچنان به کشف کاربردهای جدیدی در این زمینه ادامه میدهند. به عنوان مثال، آزمایشگاه NovaSky در دانشگاه کالیفرنیا، برکلی نشان داد که تقطیر به خوبی برای آموزش مدلهای استدلال زنجیرهای کار میکند، که از تفکر چند مرحلهای برای پاسخ به سوالات پیچیده استفاده میکنند. این آزمایشگاه مدعی است که مدل Sky-T1، که به طور کامل متنباز است، کمتر از ۴۵۰ دلار برای آموزش هزینه داشته و نتایجی مشابه با یک مدل بزرگتر متنباز به دست آورده است. دچنگ لی، دانشجوی دکتری برکلی و یکی از رهبران تیم NovaSky میگوید:
«ما واقعاً از اینکه تقطیر در این زمینه چقدر خوب عمل کرد، شگفتزده شدیم. تقطیر یک تکنیک بنیادی در هوش مصنوعی است.»
نتیجهگیری
بنابراین، تقطیر نه تنها به شرکتها کمک میکند که مدلهای هوش مصنوعی خود را کوچکتر و ارزانتر کنند، بلکه به آنها این امکان را میدهد که با حفظ دقت، به کارایی بیشتری دست یابند. در دنیای پرشتاب هوش مصنوعی، این تکنیک به عنوان ابزاری با ارزش در دست محققان و مهندسان شناخته میشود و نویدبخش آیندهای روشنتر برای توسعه فناوریهای هوش مصنوعی خواهد بود.
این مقاله به بازتاب تحولات و روندهای جدید در صنعت هوش مصنوعی پرداخته و به ما یادآوری میکند که هر نوآوری ممکن است به معنای فرصتی برای رشد و پیشرفت باشد.






دیدگاهتان را بنویسید